構造化データとは?メリットや種類・マークアップ・ツールなど初心者にわかりやすく解説!
構造化データとは、Webページの構造を検索エンジン(Google)により分かりやすく伝えるためにHTMLにマークアップする専用のコードのことです。
この構造化データは、あらかじめ「schema.org」で定義されてる専用のプロパティ(属性)とバリュー(属性値)を用いてHTMLにマークアップします。
構造化データをマークアップ(構造化マークアップ)すれば、クローラーがコンテンツ内容を認識しやすくなるので、その分Webページ(ブログ記事)のインデックスが促進されます。
そうなれば、Googleに評価されやすくなるので、SEOの良い効果が見込めるでしょう。
一方、構造化データを記述しなければ、クローラビリティが上がりません。
そうなれば、クローラーにおけるコンテンツの理解のしやすさが促進できないので、その分Googleから評価されづらくなるでしょう。
こうした良くない状況を回避する為に、構造化データを適切にマークアップして、わかりやすいコンテンツにしましょう。
この点踏まえて、今回は、構造化データの定義やマークアップ方法(実装方法)など中心に、初心者にもわかりやすくポイントをまとめて解説したいと思います。
構造化データとは?
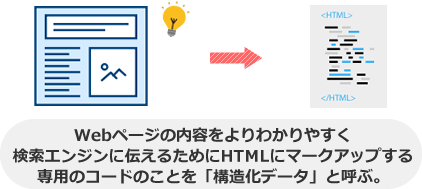
構造化データとは、Webページの内容を検索エンジン(主にGoogle/Yahoo/Bing)により解りやすく伝えるためにHTMLにマークアップする専用のコードのことです。
この構造化データは、セマンティックWebという考えのもとにあります。
セマンティック・ウェブ(英: semantic web)は W3C のティム・バーナーズ=リーによって提唱された、ウェブページの意味を扱うことを可能とする標準やツール群の開発によってワールド・ワイド・ウェブ[1]の利便性を向上させるプロジェクト。セマンティック・ウェブの目的はウェブページの閲覧という行為に、データの交換の側面に加えて意味の疎通を付け加えることにある。
セマンティック・ウェブはXMLによって記述した文書にRDFやOWLを用いてタグを付け加える。この、データの意味を記述したタグが文書の含む意味を形式化し、コンピュータによる自動的な情報の収集や分析へのアプローチが可能となると期待されている。
セマンティックウェブはXML、XML Schema、RDF、RDF Schema、OWLなどの標準およびツール群から構成されている。
※引用元:セマンティック・ウェブ – Wikipedia
このように、Webページの情報をコンピュータシステムが自動的により詳しく解釈できるようにするというセマンティックWebの構想を実現するために、「構造化データ」が必要となります。
構造化データは、あらかじめ「schema.org」で定義されてる複数のボキャブラリー(プロパティ/キー[属性]とバリュー[属性値])から選択して、用途に合わせながらマークアップします。
※ちなみに、「schema.org」は、構造化データを作成したり、管理する公式の団体のことで、Googleがサポートしてます。
マークアップできる構造化データの形式/仕様(シンタックス)は、基本的に「JSON-LD」「microdata」「RDFa」の3つがありますが、中でもGoogleは「JSON-LD」を推奨してます。
JSON-LDを使った構造化データマークアップ例:
|
1 2 3 4 5 6 7 8 |
<script type="application/ld+json"> { @context: "http://schema.org", @type: "Person", name: "札幌 太郎", birthDate: "2019-09-25" } </script> |
このように構造化データをマークアップするにあたり、「構造化データに関するガイドラインに準拠する」ことが重要です。
このガイドラインに準拠しなければ、構造化データをマークアップしてもカルーセルなどのリッチリザルト(Google検索の拡張機能)に表示されません。
また、マークアップした構造化データがスパムとして認識されてサイトの質が落ちてしまう可能性もあります。
こうした状況を回避するためにも、「構造化データの形式」「Webページ自体のクローラビリティ」「コンテンツ自体の質(インデックスされてる良質なコンテンツ)」「構造化データの関連性/具体性/完全性(コンテンツ内容にマッチする適切なプロパティとバリューを用いて正確に記述)」「構造化データの記述場所(適切な場所に記述)」といった技術面と品質面を考慮しながら、構造化データを用いるようにしましょう。
そうすれば、カルーセルなどのリッチリザルト(Google検索の拡張機能)が表示されて、その分新たな検索流入の経路が増えたり、Webページの情報がより認識しやすくなってクローラビリティが向上するといった大きなメリットが生まれます。
構造化データのメリット
構造化データのメリットがいくつかあります。
- 検索エンジンがコンテンツを理解しやすくなる
- 検索結果にリッチリザルトが表示される
検索エンジンがコンテンツを理解しやすくなる
構造化データのメリットは、検索エンジンがコンテンツを理解しやすくなることです。
例えば、Webページのタイプがブログ記事だとします。
この場合、「BlogPosting」「mainEntityOfPage」といったプロパティ(属性)とバリュー(属性値)を主に用いて、ブログ記事専用の構造化データをマークアップします。
そうすれば、クローラー(Googlebot)がクロールしたWebページのタイプを見つけてブログ記事であることを理解できます。
つまり、検索エンジンがコンテンツを理解しやすくなるというわけです。
このように、検索エンジンがコンテンツを理解しやすくなる点が、構造化データのメリットです。
検索結果にリッチリザルトが表示される
構造化データのメリットは、検索結果にリッチリザルトが表示されることです。
例えば、パンくずリストに対して、@type属性で「BreadcrumbList」を指定して、パンくずリスト専用の構造化データをマークアップします。
この場合、パンくずリストの部分を明示できます。
そうすれば、Googlebotがクロールしたときに、パンくずリストを見つけて内容を理解することができます。
結果、検索エンジンの検索結果にリッチリザルトとして表示されるわけです。
このように、検索結果にリッチリザルトが表示される点が、構造化データのメリットです。
ちなみに、パンくずリスト以外に、飲食店や販売店であればレビューや価格、在庫状況、クチコミなどの情報もあります。これらの情報を専用の構造化データでマークアップすれば、検索結果にリッチリザルトで表示できます。
構造化データのデメリット
構造化データのデメリットがいくつかあります。
- 専門知識が必要
- 実装に時間がかかる
専門知識が必要
構造化データのデメリットは、専門知識が必要なことです。
例えば、基本的にはJSON-LD形式の構造化データを使いますが、「microdata」「RDFa」といった形式もあります。これらの形式によって記述方法が異なります。
また、構造化データには、複数のボキャブラリー(属性や属性値)があり、定期的に新しいボキャブラリーも増えます。
この場合、まず記述方法を習得して、新しいボキャブラリーまで都度覚えていく必要があります。
つまり、専門知識が必要というわけです。
このように、専門知識が必要な点が、構造化データのデメリットです。
実装に時間がかかることがある
構造化データのデメリットは、実装に時間がかかることがあることです。
例えば、マークアップした構造化データの内容が正しいか否か、ツールで確認します。
確認は、構造化データテストツールやリッチリザルトテスト、サーチコンソールの「解析不能な構造化データ」項目で行います。
この場合、エラーが出る可能性があります。
エラーが出れば、そのエラーを修正して検証し改善します。改善しなければ、繰り返し修正を行う必要があります。
つまり、実装に時間がかかることがあるというわけです。
このように、実装に時間がかかることがある点が、構造化データのデメリットです。
もちろん、構造化データのマークアップに慣れれば、エラーが出ずにスムーズな実装が行えるでしょう。
構造化データのマークアップ方法

構造化データをマークアップするには、基本的にHTMLファイルに直接専用のコードをマークアップします。
また、HTMLファイルが直接編集できない場合は、「構造化データマークアップ支援ツール」や「データハイライター」などのツールを活用して構造化データをマークアップすることができます。
- HTMLファイルに直接マークアップする
- ツールでマークアップする
HTMLファイルに直接マークアップする

HTMLファイルに直接マークアップするには、まず、構造化データを追加したいHTMLファイルを専用のソフト(HTMLファイルが編集できるソフト)で開きます。
そして、開いたHTMLファイルに書かれてる既存のHTMLコードに、Google推奨の「JSON-LD」で構造化データをheadタグ内に追記します。
ちなみに、WordPressでサイト構築してる場合は、WordPressのテンプレートに適用させるために専用のWordPressタグや関数を用いて、構造化データをマークアップしましょう。
通常のHTMLファイルに記述する
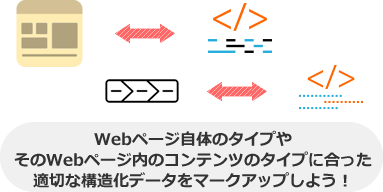
通常のHTMLファイルに記述する場合は、「schema.org」であらかじめ定義されてるプロパティ(属性)とバリュー(属性値)以外、特別なタグなどはマークアップしません。
なので、ページやコンテンツのタイプを考慮して「ページのURL」「タイトル名」「画像ファイルのURL/サイズ」「公開日/更新日(日付)」「著者名」などのボキャブラリー(プロパティとバリュー)を用いながら、以下のように構造化データをマークアップしましょう。
ブログ記事用の構造化データマークアップ例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
<script type="application/ld+json"> { "@context": "http://schema.org", "@type": "BlogPosting", "mainEntityOfPage":{ "@type":"WebPage", "@id":"https://seolaboratory.jp/91744/" }, "headline":"SEOとは?SEO対策についてについて", "image": { "@type": "ImageObject", "url": "https://seolaboratory.jp/wordpress/wp-content/uploads/2018/05/seo_taisaku.png", "height": 250, "width": 785 }, "datePublished": "2019-02-08T12:10:35+09:00", "dateModified": "2019-08-19T17:43:49+09:00", "author": { "@type": "Person", "name": "SEOラボ" }, "publisher": { "@type": "Organization", "name": "SEOラボ", "logo": { "@type": "ImageObject", "url": "https://seolaboratory.jp/images/header_logo.gif", "width": 204, "height": 52 } }, "description": "SEO対策とは、インターネット検索結果で自身のWebサイトを上位表示させたり、より多く露出させるための対策のことです。" } </script> |
※参考:記事 | 検索 | Google Developers
上記は、当ブログ「SEOラボ」の記事ページで実際にマークアップしてるJSON-LDの構造化データで、ブログの記事ページに必要な「BlogPosting」「mainEntityOfPage」といったプロパティ(属性)とバリュー(属性値)を主に用いて構造化データをマークアップしてます。
一方、ここで例に挙げたようなブログの記事ページではなく、ニュースの記事ページであれば、記事のタイプが異なる(@typeプロパティの属性値が「NewsArticle」に変わる)ので、マークアップできる構造化データも少し変わります。
また、記事ページの中には、パンくずリストがコンテンツ内に盛り込まれてます。
そうなれば、記事ページの構造化データに付け加えて、「パンくずリスト」用のプロパティとバリューを使って、構造化データを追記します。
さらに、AMPページがあれば、AMPページを構成するAMP HTMLファイルに、別途、AMP用の構造化データをマークアップする必要があります。
このように、コンテンツのタイプ(種類)によってマークアップできる構造化データが決まってるというわけです。
こうしたJSON-LDの構造化データは、主に3つのマークアップがベースとなります。
JSON-LDの構造化データマークアップを宣言する
|
1 2 3 4 |
<script type="application/ld+json"> { } </script> |
JSON-LDの構造化データをマークアップするために、script要素で application/ld+json を指定します。
そうすれば、括弧内に有効なJSON-LDの構造化データを記述することができます。
@context属性を宣言する
|
1 |
"@context": "http://schema.org", |
@contextのプロパティで、http://schema.org の属性値を指定して、schema.orgを使った構造化データを記述することを宣言します。
そうすれば、http://schema.org で定義されてるボキャブラリー(プロパティやバリュー)を使って、有効なJSON-LDの構造化データを自由にマークアップすることができます。
@type属性を指定する
|
1 |
"@type": "BlogPosting", |
@typeのプロパティで、表現するもの(何について表現するか?) を指定します。
例えば、@typeのプロパティで、BlogPostingの属性値を指定すれば、ブログ記事について表現することができます。
つまり、ブログ記事に関する具体的な情報を、構造化データで記述できるようになるというわけです。
そして、基本的に、@typeで指定した属性値にまつわるプロパティ(nameやurlなど)を、@type以降にマークアップします。
そうして、各コンテンツの具体的な情報を増やすようにして、有効なJSON-LDの構造化データをマークアップします。
WordPressのテンプレートに記述する
WordPressでサイト構築してる場合は、「通常のHTMLファイルに記述する」で紹介したコードをベースに、別途、WordPressのテンプレート(HTMLファイル)用に適用させる必要があります。
例えば、ページごとに変化する部分(値)に対応するために、部分的に変数を追記したり、バリュー(属性値)を関数やWordPressタグに変換して、以下のように構造化データをマークアップします。
ここでは、WordPressで構築してる当ブログ「SEOラボ」の記事ページのテンプレートでマークアップしてる構造化データを例にして紹介します。
ブログ記事用の構造化データマークアップ例:(WordPressの場合)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
<?php $thumbnail_id = get_post_thumbnail_id($post); $imageobject = wp_get_attachment_image_src( $thumbnail_id, 'full' ); ?> <script type="application/ld+json"> { "@context": "http://schema.org", "@type": "BlogPosting", "mainEntityOfPage":{ "@type":"WebPage", "@id":"<?php the_permalink(); ?>" }, "headline":"<?php the_title(); ?>", "image": { "@type": "ImageObject", "url": "<?php echo $imageobject[0]; ?>", "height": <?php echo $imageobject[2]; ?>, "width": <?php echo $imageobject[1]; ?> }, "datePublished": "<?php echo get_date_from_gmt(get_post_time('c', true), 'c');?>", "dateModified": "<?php echo get_date_from_gmt(get_post_modified_time('c', true), 'c');?>", "author": { "@type": "Person", "name": "SEOラボ" }, "publisher": { "@type": "Organization", "name": "<?php bloginfo('name'); ?>", "logo": { "@type": "ImageObject", "url": "https://seolaboratory.jp/images/header_logo.gif", "width": 204, "height": 52 } }, "description": "<?php echo mb_substr(strip_tags($post-> post_content),0,70).'...'; ?>" } </script> |
上記のように、「ページのタイトル名」「ページのURL」「画像のURL/サイズ」「公開日/更新日」といったページごとに属性値が変わる部分を、WordPressタグ/関数に置き換えて構造化データをマークアップします。
また、冒頭で変数を定義して、image属性でマークアップしてるアイキャッチ画像のURLとサイズの値がページごとに変換されるようにコードを記述します。
さらに、logo属性は、ページごとに変化するものではないので、WordPressタグ/関数に置き換えてません。
ちなみに、先述したように「パンくずリスト」などのコンテンツに対して構造化データをマークアップする際も同様に、ページごとに属性値が変わる部分をWordPressタグ/関数に変換しましょう。
こうしてマークアップするためには、まず、「通常のHTMLファイルに記述する」で解説してるような一般的な構造化データのコードを用いましょう。
そして、そのコードをベースにして、ページごとに属性値が変わる部分をWordPressタグ/関数に変換したり、変数を追記して、WordPressのテンプレートに構造化データをマークアップするのがおすすめです。
ツールでマークアップする
ツールでマークアップするには、「構造化データマークアップ支援ツール」を活用します。
例えば、構造化データマークアップ支援ツールのページにGoogleアカウントでログイン後、構造化データのタイプで「記事」を選択して、ブログの記事ページのURLを入力し、「タグ付けを開始」ボタンをクリックします。
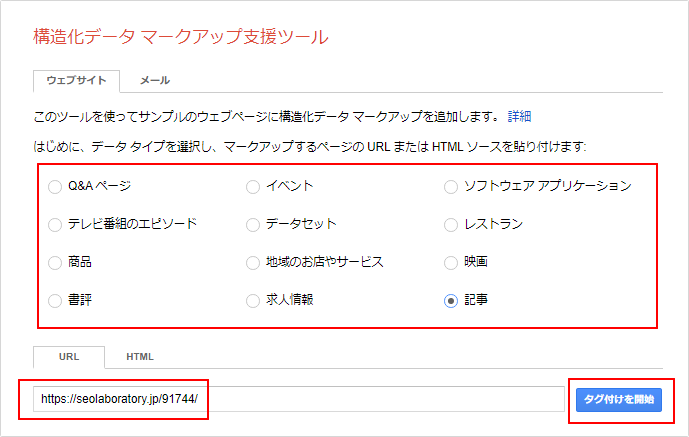
そして、読み込まれた記事ページのメインテーマである「SEOとは?SEO対策についてについて」をドラックして表示される項目から、「記事のセクション」を選択します。
そうすれば、右のマイデータアイテムの記事のセクションに、「SEOとは?SEO対策についてについて」が、挿入されます。
つまり、メインテーマである「SEOとは?SEO対策についてについて」を、記事のセクションの構造化データとしてマークアップすることができます。
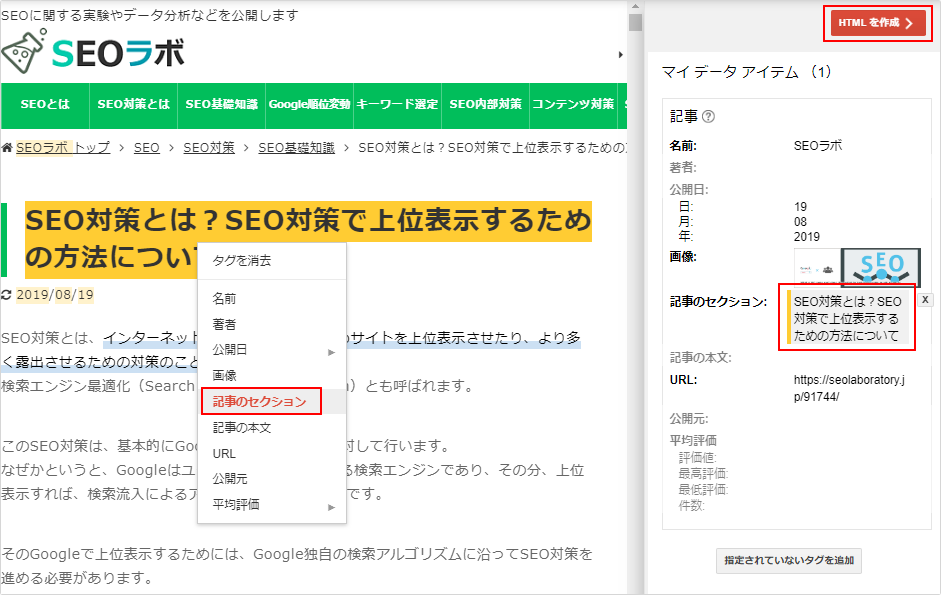
こうして、その他表示される項目(著者/公開日/画像/記事セクション/記事本文/URL/公開元など)に該当するコンテンツ(テキストや画像)をドラックしたり、クリックして右のマイデータアイテムを埋めます。
わかる範囲でマイデータアイテムを埋めたら、画面右上の「HTMLを作成」ボタンをクリックします。
そうすれば、マイデータアイテムの内容をJSON-LDの構造化データで出力できます。
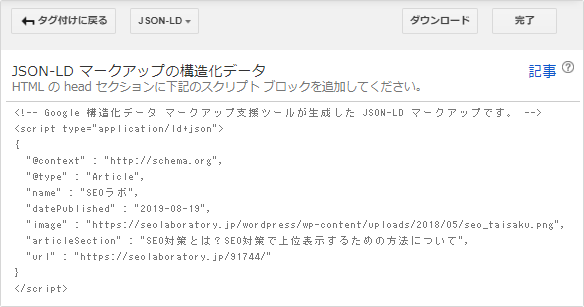
結果的に、上記のように、自身のブログの記事ページの構造化データをマークアップすることができます。
ちなみに、ここで紹介した構造化データマックアップ支援ツールと似た「データハイライター」というツールを使えば、構造化データのマークアップからクロールまで一貫して行うことが可能です。
そのデータハイライターを使うには、構造化データをマークアップしたいサイトを、あらかじめサーチコンソールに登録しておく必要があります。
しかし、こうしたツールでマークアップできる構造化データで用意されてるプロパティは限定的なものになります。
さらに言えば、デフォルトで用意されてる構造化データ以外をツールから手動で追加できますが、そうなれば、コンテンツ内容にそぐわない不適切な構造化データをマークアップしてしまう可能性が高くなります。
なので、ツールを使ってマークアップした構造化データのコード内容を、構造化データテストツールでチェックすると、基本的にエラーや警告が出やすくなります。
こういった状況を回避するためにも、ツールを使わずに手動でHTMLファイルに構造化データをマークアップするための技術を身に付けておくことをおすすめします。
そのためには、まず、Google公式サイトに掲載されてる「検索ギャラリー」の機能で該当の構造化データのタイプから「使ってみる」ボタンをクリックします。
そして、表示される例の「マークアップを参照」をクリックすれば、JSON-LDの構造化データのサンプルコードが取得できるので、それをベースに手動でマークアップを進めてみましょう。
ちなみに、先述した「通常のHTMLファイルに記述する」は、JSON-LDの構造化データのサンプルコードをベースに、SEOラボのブログ記事用にカスタマイズしてマークアップしてるので、ぜひご参考ください。
構造化データの有効性を確認する方法
構造化データをマークアップしても、有効性に問題があれば検索エンジンに認識されません。
そうなれば、リッチリザルト(リッチスニペット)が表示されなかったリ、Webページ内容の認識が促進できないので、結果的に検索パフォーマンスの向上に至らないことになります。
こうした状況を回避するためにも、本番に反映(アップロード)する前に、マークアップした構造化データが有効かどうか?を「構造化データテストツール」で検証しましょう。
例えば、構造化データテストツールにアクセス後、「コードスニペット」に切り替えて、本番に反映する予定の構造化データのコードをコピペして、「テストを実行」します。
※既に構造化データをマークアップしたページURLを本番公開してる場合は、「URLを取得」からテストを実行できます。
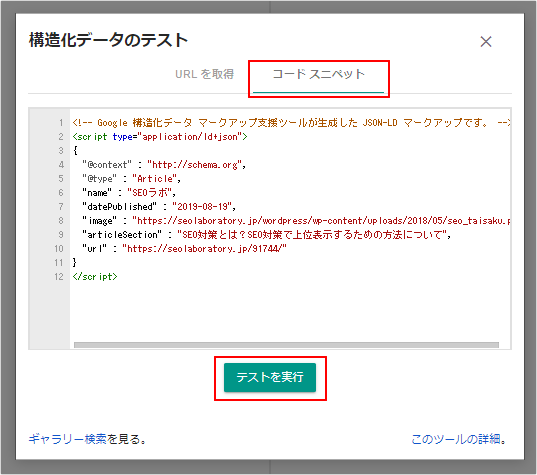
以下のように、エラーや警告が出れば、該当の項目を適宜修正します。
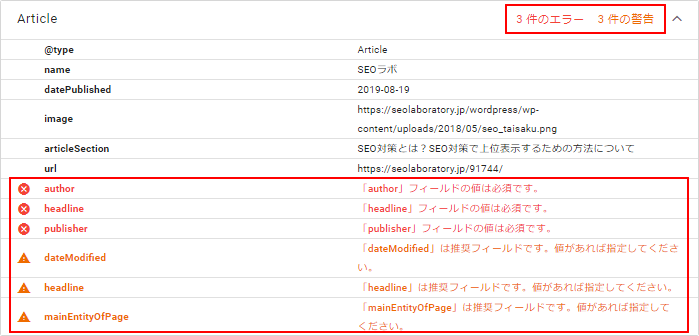
修正後、再チェックして、以下のように「エラーなし 警告なし」と表示されれば、構造化データのマークアップが有効となります。

こうして、有効な構造化データがマークアップされたHTMLファイル(記事ページ)をアップロードしましょう。
そして、アップロードした記事ページのURLを、URL検査ツール(旧:Fetch as Google)を使ってクロール促進して、検索エンジン(Google)に構造化データの内容をより確実に認識させましょう。
ちなみに、構造化データの有効性は、サーチコンソールの拡張メニューにある「解析不能な構造化データ」の項目でも確認できます。
これは、本番に反映後、構造化データの有効性に問題があった場合に、アラート表示されます。

構造化データのSEO効果
構造化データをマークアップしても、直接的なSEO効果は見込めません。(直接的なSEOへの影響はない。)
これについては、Googleのジョンミュラー氏が公式に言及してます。
原文:
you’re marking it up like this that’s really nice of you but we’re not using that to change rankings翻訳:
あなたはこのように(構造化データ)をマークアップしているのはあなたにとって本当に素晴らしいことですが、私たちはそれをランキングの変更に使用していません
※引用元:
このように、直接的なSEO効果はありませんが、構造化データをマークアップすることで、クローラビリティが向上するので、間接的なSEO効果が期待できます。
例えば、「schema.org」で定義されてるタグを用いて、構造化データをWebページにマークアップします。
そうすれば、クローラーがWebページ内のコンテンツ情報をより理解しやすくなるので、クローラビリティが向上します。
結果的に、ただのページよりも、コンテンツ情報が明確なページをインデックスさせることができるので、その分Googleに評価されやすくなるというわけです。
また、カルーセルといったリッチリザルト用の構造化データをマークアップすれば、新たな検索流入の経路が増えます。
そうなれば、サイトへ流入するユーザーが増加して、コンテンツの共有や参照される機会が増えるので、その分、サイテーションや被リンク獲得の促進につながります。
結果的に、外部要因が強化されるので、その分、Googleに評価されやすくなるというわけです。
このように、構造化データをマークアップしてWebページのクローラビリティを高めたり、Webページへの検索流入を拡大させることで、間接的なSEO効果が見込めるでしょう。
まとめ:構造化データを適切にマークアップして、わかりやすいコンテンツにしよう
コンテンツ情報との整合性を考慮して、適切な構造化データをマークアップしましょう。
そうすれば、クローラビリティが高まって、Webページの質を向上させることができます。
また、適切な構造化データをうまく使えば、リッチリザルトによる検索流入の拡大が見込めます。
そうなれば、サイトのエンゲージメントが向上するので、この点においてもWebページの質が高まります。
こうして、Webページの質が高まれば、Googleに評価されやすくなるので、SEO効果が期待できるようになります。
こうしたSEO効果を最大限引き出すためには、ユーザーの検索意図(ユーザーが求める情報)を考慮したWebページに仕上げることが最も重要です。
そして、ユーザーが求める情報の量(網羅性/包括性)、手に入れやすさ(簡便性)、信憑性(正確性)、独自性まで加味して良質なWebページに仕上げましょう。
こうした、良質なページを増やして、専門性や権威性、ユーザビリティ、クローラビリティを織り交ぜたより信頼できるサイトにすることがSEO対策で上位表示を目指すためのポイントとなります。
SEO対策しても検索順位が上がらない…なぜ?
SEO対策しても検索順位が上がらない…なぜ?
検索順位が上がらない理由は、SEO対策の質が低いからです。
例えば、ユーザーの検索意図を無視したり、関連性の低いコンテンツを増やす、内部リンクの最適化など疎かにします。
この場合、SEO対策の質が下がります。
そうなれば、ページやサイト自体の品質が上がらないので、Googleに評価されづらくなります。
結果、検索順位が上がらないというわけです。
こうした悪い状況を回避する為に、サイトの欠点を調査して上位化に必要な対策をご案内します(無料)。
検索順位を上げたり、検索流入を増やすにはSEOが重要!