クローラーとは?意味やSEOでの仕組み、対策などわかりやすく解説!
クローラーとは、インターネット上にあるWebサイトの文章や画像などの情報を取得して、自動的に検索データベース化する巡回プログラムのことです。
このプログラムは、 「ボット(Bot)」「スパイダー」「ロボット」などとも呼ばれます。
とくに、Googleの検索エンジンの場合「Googlebot」と呼ばれるクローラー(Googleクローラー)があります。
このクローラーに巡回(クロール/クローリング)されやすくしてクローラビリティを向上させれば、ユーザーにWebサイトの情報をきちんと届けることができます。
これは、有効なSEOとなります。
一方、クローラビリティが悪ければ、Webサイトの情報が認識されづらいです。
この場合、インデックスされなかったり、不完全な情報がインデックスされます。
結果、検索ユーザーにWebサイトの情報がきちんと届かなかったり、検索順位や検索流入の向上に繋がりません。
こうした良くない状況を回避する為に、クローラーの仕組みを理解して、クローリングされやすいコンテンツにしましょう。
この点踏まえて今回は、クローラーの意味や仕組み、クローラー対策(クローリング対策/クロール対策)など中心に、初心者にもわかりやすくポイントをまとめて解説したいと思います。
クローラーとは?
クローラーとは、インターネット上にあるWebサイトの文章や画像などの情報を取得して、自動的に検索データベース化する巡回プログラムのことです。
このプログラムは、 「ボット(Bot)」「スパイダー」「ロボット」などとも呼ばれます。
例えば、ドメインを取得して作成したWebサイトをサーバーにアップロードしたとします。
この場合、インターネット上にWebサイトが公開されたことになります。
このWebサイトの文章や画像などの情報を取得するために、専用のプログラムが巡回(クロール/クローリング)します。
このプログラムが、クローラーというわけです。
クローラーの機能は検索エンジンの仕組みの一部
クローラーの機能は、検索エンジンの仕組みの一部です。
例えば、GoogleやYahoo、Bing(Microsoft) などの検索エンジンは、ほとんどがロボット型検索エンジンです。
このロボット型検索エンジンは、主に3つの仕組みで構成されてます。
- インターネット上で収集したWebサイトのページ情報をデータベースに登録
- データベースに登録されたページのランク付け
- ランク付けされたページを検索結果に表示
これらの仕組みの中で、「①インターネット上で収集したWebサイトのページ情報をデータベースに登録」の役割を担うのがクローラーです。
クローラーは、既にデータベース化されているWebサイトからリンクをたどって自動的に移動(クローリング)します。移動先ではページの解析(パーシング)を行って、そのページの情報を処理します。処理したページ情報を検索アルゴリズムが扱いやすいデータに変換してデータベースに登録します。
このように、検索エンジンの仕組みの一部として、クローラーの機能があるとうわけです。
クローラーの種類
クローラーの種類が、いくつかあります。
例えば、
クローラーは検索エンジンごとに存在します。
- Googlebot(Google)
- Bingbot(マイクロソフト社の検索エンジンBing)
- Yahoo Slurp(日本以外のYahoo!)
- Baiduspider(百度)
- Yetibot(Naver)
- ManifoldCF(Apache)
- AppleBot(Apple)
これらのクローラー以外にも、Googleであれば、画像検索用のGooglebot-Image、モバイル検索用のGooglebot-Mobileなど多数のクローラーが存在します。
クローラーが取得するファイルの種類
クローラーが取得するファイルの種類がいくつかあります。
例えば、Googleのクローラーであれば、HTMLや画像/動画、JavaScript、CSS、PDFなどのファイル形式がクローリングの対象です。
- HTML
- 画像
- 動画 – サポートされている動画形式のいずれか。
- JavaScript
- CSS
- その他の XML – XML をベースとした RSS、KML などの形式を含まない XML ファイル。
- JSON
- シンジケーション – RSS フィードまたは Atom フィード
- 音声
- 地理データ – KML または他の地理データ。
- その他のファイル形式 – ここに記載されていないその他のファイル形式。
- 不明(失敗) – リクエストが失敗した場合、ファイル形式は不明となります。
また、その他の検索エンジンのクローラーも基本的に、Googleと同様のファイル形式をクローリングできると思われます。
クローラー対策(クローリング対策/クロール対策)
クローラー対策がいくつかあります。
- XMLサイトマップを設置する
- 質の高いページを作成する
- シンプルなURLにする
- 重複ページを無くす
- 内部リンクを最適化する
- 被リンクを増やす
- ファイルのサイズを減らす
- サーバーを最適化する
- ソフト404エラーを無くす
- ファイルのクロールを拒否する
- 不要なアクセスをブロックする
- URL検査ツールを使う
XMLサイトマップを設置する

クローラー対策は、XMLサイトマップを設置します。
例えば、まず、「sitemap.xml Editor」を使って作成したXMLサイトマップ(sitemap.xml)を、サーバーにアップロード(設置)します。
そして、「xxxx.jp/sitemap.xml」のようなXMLサイトマップの存在を示すURLにアクセスできるので、そのURLをサーチコンソールのサイトマップから送信します。
そうすれば、sitemap.xmlファイル内に記載したURLを、優先的にクロールすることをGoogleに伝えることができます。
結果、サイト内のページごとにクローラーを呼び込むことができるので、クローラビリティの促進に繋がるというわけです。
こうして、XMLサイトマップを設置することが、クローラー対策です。
ちなみに、WordPressで構築したブログであれば、「Google XML Sitemaps」などの専用プラグインを導入しましょう。
質の高いページを作成する

クローラー対策は、質の高いページを作成します。
例えば、SEOキーワード(上位表示したいキーワード)で検索して表示される競合上位のサイトのタイトル名やコンテンツ内容の傾向を採用して、自身のWebページを作成します。
その際に、タイトル名にSEOキーワードを入れます。
そうすれば、ユーザーの求める情報(検索意図)が盛り込まれるので、質の高いページに仕上がります。
さらに、ユーザーが求める情報の量(網羅性/包括性)や手に入れやすさ(簡便性)、信憑性、独自性を加味すれば、より質の高いページに仕上がります。
質の高いページとなれば、基本的にクローラーが巡回しやすくなるので、クローラビリティが良くなるというわけです。
サイトに非常に有用な情報が掲載されている場合は、想定を上回ってクロールされてしまう可能性があります。
※引用元:クロールの統計情報レポート(ウェブサイト) – Search Console ヘルプ
こうして、質の高いページを作成することが、クローラー対策です。
付け加えると、「有用な情報の追記/新規追加、不要な情報の削除(更新)」や「テキスト中心のコンテンツ作成」「適切なHTMLタグや構造化データによるマークアップ」を考慮してページ作成することでも、質を高めることができるので、クローラビリティの向上に繋がります。
シンプルなURLにする

クローラー対策は、シンプルなURLにします。
例えば、「SEOとは?」というタイトル名なら、「search-engine-optimization」という文字列を使いたくなりますが、略称の「seo」という短い文字列を用いたURLにします。
そうすれば、全体的な文字列が短くなって、簡潔なURLにすることができるので、クローラビリティが良くなります。
こうして、シンプルなURLにすることが、クローラー対策です。
また、当ブログ「SEOラボ」のように、「投稿ID」を文字列に使った短いURL(URL例:seolaboratory.jp/91744/)にしたり、カテゴリ名の短さやカテゴライズの必要性を考慮します。
そうすれば、全体的な文字列を減らしてシンプルなURLできるので、クローラビリティの改善に繋がるでしょう。
重複ページを無くす
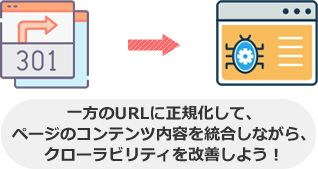
クローラー対策は、重複ページ(重複コンテンツ)を無くします。
例えば、「www.seolaboratory.jp」と「seolaboratory.jp」のwww有り無しのURLにそれぞれアクセスでき、かつ同じコンテンツ内容が表示されるとします。
この場合、重複ページです。
なので、「www.seolaboratory.jp」から「seolaboratory.jp」のURLへ301リダイレクトを実装してwwwあり・なしを統一します。
そうすれば、「seolaboratory.jp」のURLが正規URLとしてGoogleに認識されるようになるので、重複ページの回避に繋がります。
結果、「www.seolaboratory.jp」のURLに対するクロールの浪費が減るので、その分クローラビリティが良くなるというわけです。
こうして、重複ページを無くすことが、クローラー対策です。
また、「canonicalタグ」「rel=”canonical” HTTP ヘッダー」「サイトマップ」を活用して、正規URLをGoogleに伝えることでも、重複ページの回避につなげることができます。
さらに、AMPページに「canonicalタグ」、個別のスマホ向けページに「alternateタグ」をマークアップしてURL正規化することも、重複ページを回避するための重要な対策です。
内部リンクを最適化する

クローラー対策は、内部リンクを最適化することです。
例えば、トップページのコンテンツから下層ページ(カテゴリ一覧ページや記事ページなど)に向けてリンク(内部リンク)を設置します。
また、専用のナビゲーションページ(HTMLサイトマップ)を作って、そのページへのリンクをサブコンテンツに設置します。
そうすれば、それらの内部リンクを辿ってクローラーがサイト内の各ページを巡回します。
結果、クロールの範囲が広がって、クローラビリティが良くなるというわけです。
こうして、内部リンクを最適化することが、クローラー対策です。
被リンクを増やす
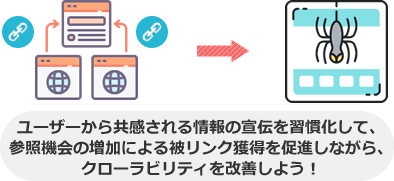
クローラー対策は、被リンクを増やします。
例えば、TwitterやFacebookなどのアクティブユーザーが多いSNSで、自身のWebサイト内の質の高いページURLや為になる関連情報を定期的に宣伝します。
そうすれば、共有が促進されて、外部サイトでの参照が増えやすくなります。
結果的に、被リンクが増えて、外部サイトからクローラーが巡回しやすくなるので、クローラビリティが良くなるというわけです。
こうして、被リンクを増やすことが、クローラー対策です。
また、被リンクが増えて、人気度の高いWebページとなれば、根本的にそのページに対するクロールの必要性が高まります(クローラビリティが向上します)。
人気度: インターネット上で人気の高い URL ほど、Google のインデックスで情報の新しさが保たれるよう頻繁にクロールされる傾向があります。
※引用元:Google ウェブマスター向け公式ブログ [JA]: Googlebot のクロール バジェットとは?
ちなみに、「専用サービスにおける広告内のリンク」「有料リンク」「コメント内のリンク」「Googleウェブマスター向けガイドライン(品質に関するガイドライン)に準拠していないリンク」を増やしても、そういったリンクは基本的にクロールされなので、クローラビリティの向上につながりません。
ファイルのサイズを減らす
クローラー対策は、ファイルのサイズを減らします。
例えば、画像やCSS、Javascriptといったファイルを圧縮したり、不要なソースコードを削除、キャッシュの活用、AMP化などします。
そうすれば、ファイルサイズが減るので、クロールのリソースが減ります。
結果的に、クロール速度が早まったり、余ったクロールのリソースを他のコンテンツに配分できるので、クローラビリティが良くなるというわけです。
また、サイトの表示速度が上がってサイトが迅速に表示され続けると、クロールの上限が上がるので、この点においてもクローラビリティの向上が見込めます。
こうして、ファイルのサイズを減らすことが、クローラー対策です。
サーバーを最適化する
クローラー対策は、サーバーを最適化します。
例えば、ディスク(ストレージ)やメモリの容量を増やしたり、CPUの性能を高めてサーバースペックを上げます。
また、PHPのバージョン改善、サーバー分散(ロードバランサーなど)、CDNの活用、データベースの改善などします。
そうすれば、負荷が減って、サーバーの応答速度が上がりやすくなります。
結果的に、Webページに対して正常にクローラーが巡回しやすくなるので、クローラビリティが良くなるというわけです。
こうして、サーバーを最適化することが、クローラー対策です。
ソフト404エラーを無くす
クローラー対策は、ソフト404エラーを無くします。
例えば、htaccessファイルに、「ErrorDocument 404 /404.html」のコードを記述して、そのファイルをサーバーにアップロードします。
そうすれば、存在しないURLにアクセスしたときに、404.html(404エラーページ)を表示して、HTTPステータスコードで404を返す(GoogleにNot Found「未検出」「見つかりません」と伝える)ことができるので、ソフト404エラーが無くなります。
結果的に、404エラーページにクローラーが巡回しなくなって、クロールのリソースが軽減できるので、クローラビリティが良くなるというわけです。
こうして、ソフト404エラーを無くすことが、クローラー対策です。
また、HTTPステータスコードで410を返したり、404ページにnoindexを入れることでも、クローラーの巡回を回避することができます。
ファイルのクロールを拒否する
クローラー対策は、ファイルのクロールを拒否します。
例えば、重要性の低いPDFファイルに対して、Googlebot含めた全てのクローラーを巡回させないための(クロール拒否の)コードを、robots.txtファイルに記述します。
|
1 2 |
User-Agent:* Disallow: /example/sample.pdf |
こうした記述によって、特定ファイルのクロールを拒否(ブロック)することができるので、クロールの浪費を減らすことができます。
結果的に、クロール速度が速まったり、他の重要なコンテンツにクロールが再配分できるので、クローラビリティが良くなるということです。
こうして、ファイルのクロールを拒否することが、クローラー対策です。
また、PDF以外にも、ワード(.doc/.docx)や.パワーポイント(ppt/.pptx)などのファイル、決済ページ(フォーム関連)やユーザー専用のページ(会員ページ)、管理ページなども重要性が低いので、クロール拒否を検討しましょう。
不要なアクセスをブロックする

クローラー対策は、不要なアクセスをブロックします。
例えば、とくに目立ったアップデートがないのに、突如アクセス数が急増してサーバーが重くなることがあります。
この場合、Googleアナリティクスのリファラーやアクセスログからアクセス元を特定し、そのアクセス元のドメインやIPアドレスを拒否するコードをhtaccessファイルに記述します。
|
1 2 3 4 |
Order allow,deny allow from all deny from .seolaboratory.jp # 特定のドメイン deny from 192.0.2.0/24 # 特定のIPアドレス |
このように記述したファイルをアップロードすれば、deny fromで書き始めた特定のドメインやIPアドレスからのアクセスがブロックできます。
つまり、不要なアクセスがブロックできるので、サーバーの負荷が軽減できます。
結果的に、Webページを正常にクロールすることができるので、クローラビリティが良くなるというわけです。
こうして、不要なアクセスをブロックすることが、クローラー対策です。
また、Googlebotからのアクセスが多いことでサーバーに負荷が生じてる場合は、基本的にGooglebotのクロール頻度を調整するようにしましょう。
URL検査ツールを活用する
クローラー対策は、URL検査ツール(旧:Fetch as Google)を活用します。
例えば、サーチコンソールにログイン後、メニューの「URL検査」からクロールを促したい自身のサイトのページURLを検索窓に入力して、「インデックス登録をリクエスト」します。
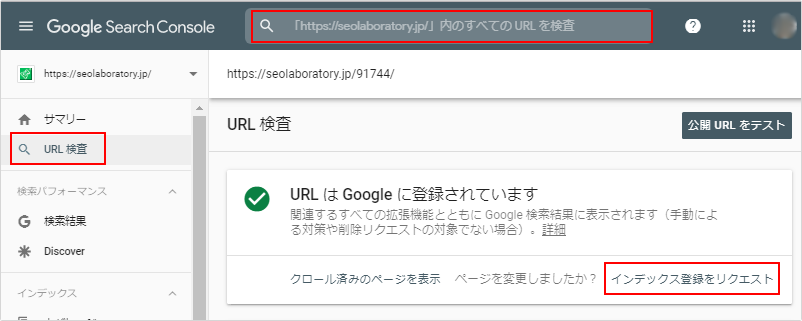
そうすれば、入力したページURLの情報をGoogleに伝えることができます。
結果、そのページへ一時的かつ強制的にクローラー(Googlebot)の巡回を促せるので、クローラビリティが良くなるとうわけです。
これは、新規ページやリライトしたページのURLに対してよく実施します。
こうして、URL検査ツールを活用することが、クローラー対策です。
ちなみに、先述したように、URL検査ツールによるインデックス登録のリクエストは、特定のページURLに対して一時的にクロールを促進するだけです。
つまり、極端に言えば、1回クロールされて終わりです。
なので、根本的にクローラビリティの低いページなら、Webページの情報がクローラーにしっかり読み取られない可能性があります。
そうなれば、インデックスが促進されないので、SEO効果が見込めません。
これを回避するためには、質の高いコンテンツ増やしてサイト自体の質を高めたり、関連する高品質ページへの内部リンクを増やすなどして、根本的にクローラビリティを良くすることが重要です。
クローラーの動きを確認する方法
クローラーの動きを確認するには、サーチコンソールを活用します。
例えば、サーチコンソールにログイン後、メニューから[設定]をクリックして、クロールの統計情報で[レポートを開く]をクリックします。
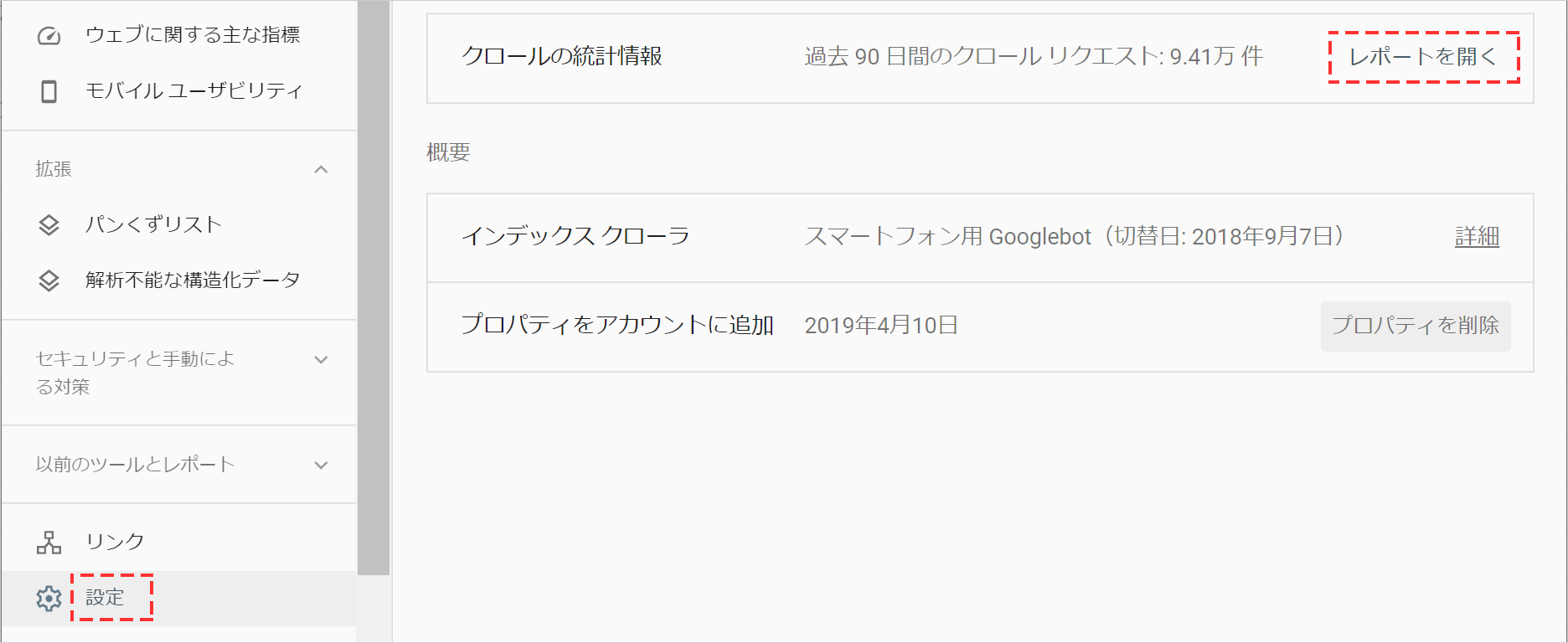
そうすれば、「クロールリクエストの合計数」「合計ダウンロードサイズ(バイト)」「平均応答時間(ミリ秒)」などの項目における90日間のホストのステータスが表示されます。さらにその下部では「レスポンス別」「目的別」「ファイル形式別」「Googlebotタイプ別」にクロールリクエストの詳細が表示されます。
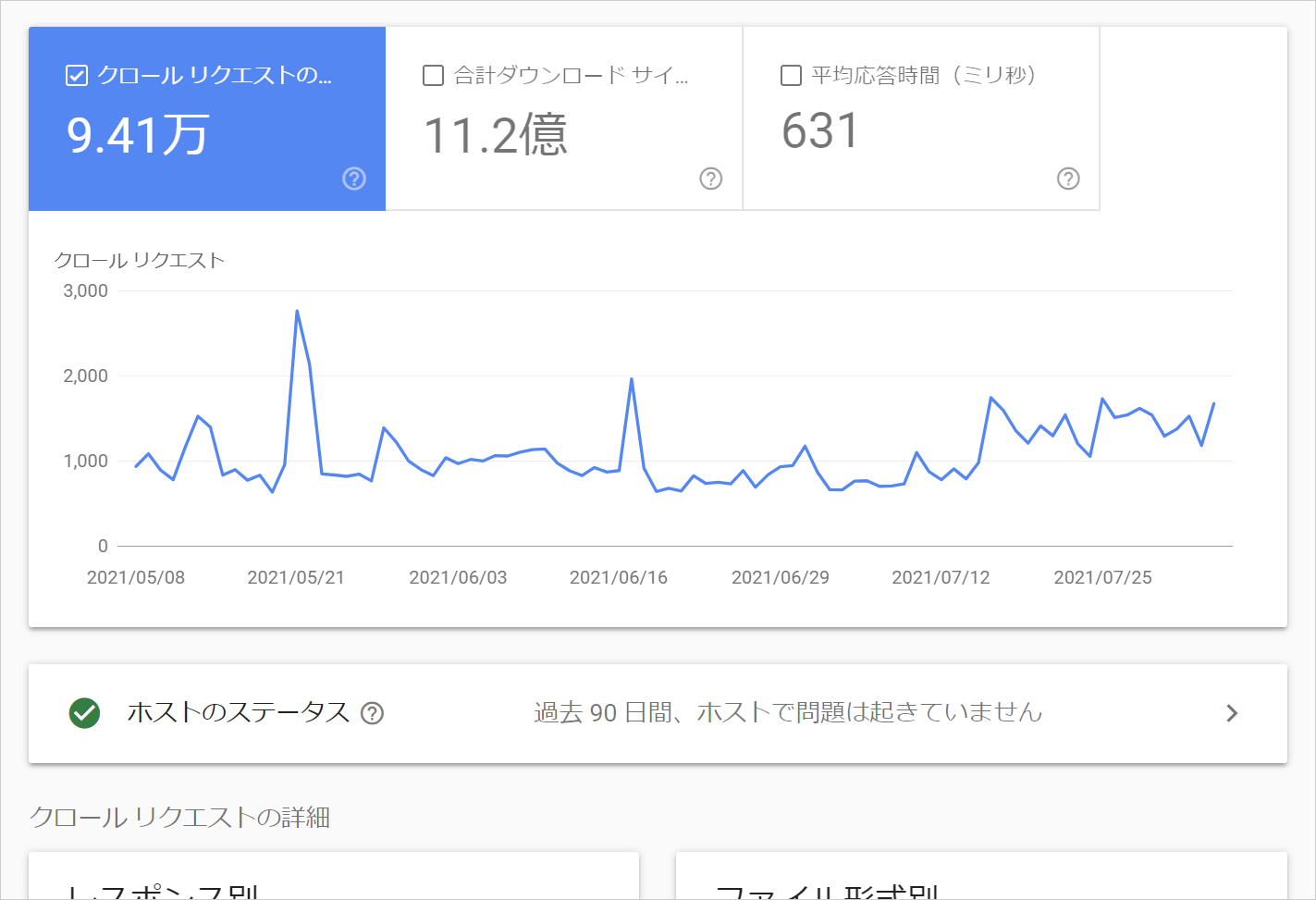
このようにクロールの統計情報が表示されるので、クローラーの動きが確認できるというわけです。
まとめ:クローラーの仕組みを理解して、クローリングされやすいコンテンツにしよう
クローラーの仕組みを理解して、クローリングされやすいコンテンツにしましょう。
一方、クローラーの仕組みがわからなければ、クローラビリティを改善する必要性もわかりません。
そうなれば、クローラーに検索されづらいサイトのままです。
結果、インデックスされなかったり、不完全なコンテンツ内容がインデックスされるサイトを運営し続けることになるというわけです。
これでは、検索順位が上がらなかったり、検索流入が増えづらいので、サイトのアクセス数が思うように伸びません。
アクセス数が増えなければ、見込み顧客の集客が滞るのでサイトからの売り上げ向上が思うように見込めないでしょう。
こうした悪い状況を回避する為に、クローラーの仕組みを理解して、クローリングされやすいコンテンツにしましょう。
SEO対策しても検索順位が上がらない…なぜ?
SEO対策しても検索順位が上がらない…なぜ?
検索順位が上がらない理由は、SEO対策の質が低いからです。
例えば、ユーザーの検索意図を無視したり、関連性の低いコンテンツを増やす、内部リンクの最適化など疎かにします。
この場合、SEO対策の質が下がります。
そうなれば、ページやサイト自体の品質が上がらないので、Googleに評価されづらくなります。
結果、検索順位が上がらないというわけです。
こうした悪い状況を回避する為に、サイトの欠点を調査して上位化に必要な対策をご案内します(無料)。
検索順位を上げたり、検索流入を増やすにはSEOが重要!