robots.txtとは?書き方や設定方法など徹底解説!
robots.txtとは、Webサイトのファイル(ページやディレクトリ)の内容を認識する「クローラー」の動作をコントロールする際に記述するテキストファイル(.txt)のことを指します。
このrobots.txtは、主にクロール制限を行う際に活用します。
クロール制限は、大規模サイトにおける膨大な不要ページに対して行うケースが多く、SEOに有効な場合があります。
またrobots.txtに、User-Agentでクローラーの種類を指定して、そのクローラーが拒否したいファイルのURLパス(特定のファイル)をDisallowで指定して記述します。
記述したロボッツテキストファイル(robots.txt)をサーバーにアップすることで、指定したクローラーがサイト内の特定ファイルを巡回しないように命令できます。
このような用途など踏まえて、今回はrobots.txtの書き方など中心に初心者にもわかりやすくポイントをまとめて解説したいと思います。

robots.txtとは?
robots.txtとは、冒頭でも少し触れましたが、サイトを巡回するクローラーの動作をコントロールするために記述するテキストファイル(.txt)のことです。
主に、クローラーにサイト内のページ(ブログ記事)やディレクトリといったファイルへの巡回を制限する指定を記述するときに robots.txt(ロボッツテキスト) を用いることが多いです。
これは、User-Agentでクローラーの種類を指定し、巡回させたくないファイルをDisallowを用いて記述することで、クローラーの巡回が制限できます。
基本的にはサイト運用の初期段階でクロール制限することはないので、「すべてのクローラーのサイト内巡回を許可する」以下の記述をして、robots.txtをサーバにアップしておくとよいでしょう。
|
1 2 |
User-Agent:* Disallow: |
その他、不要な画像やCSS、javascriptファイルへのクロールを制限してリソースを軽減したり、サイトマップの存在を知らせるための記述もできます。
このような用途が基本となりますが、とくにページ数が膨大な大規模サイトではrobots.txtによるクロール制限を「クロール最適化」として活用する手段もあり、SEOにおいても有効です。
SEOにおけるrobots.txtの重要性
robots.txtは、簡単に言うと、重要なページをうまく認識させるためのハブ役です。
重要なページは、robots.txtを積極的に利用しなくても小規模サイトであれば通常はクロールされます。
しかし、amazonや楽天などのページ数が膨大にあるような大規模なサイトでは、低品質なページや、内部リンクと被リンクが少なくてリンク階層が深いページが多く見受けられます。
そうなれば、クローラーが効率よくサイト内のWebページを巡回できないので、重要なページがクロールされない可能性があります。
このような場合に、robots.txtの活用が有効です。
例えば、不要なファイル(ページ/ディレクトリ/css/javascript/画像など)をクロール拒否して、クロールのリソースを重要なページに配分するようにクロールバジェット最適化(クロール最適化)を行う方法があります。
このように、クローラビリティを改善して、重要なページをうまくクロールさせるようにrobots.txtを活用することが、SEOにおいて重要となります。
robots.txtの書き方

robots.txtは、先述した通り、クロール制限やサイトマップの指定を行う際に利用します。
なので、これらの用途がrobots.txtにおける基本的な書き方となるので、しっかり記述方法を抑えておきましょう。
基本形式の記述
サイト運用の初期段階・通常のサイトにおいては、特定のクロールを制御する必要性が低いので、基本的に以下の記述をしておくと良いでしょう。
そして、サイトマップの設置が済んでれば、そのパスを追記しておくとなお良いでしょう。
|
1 2 3 4 |
User-Agent:* Disallow: Sitemap:http://example.com/sitemap.xml |
このようにrobots.txtを作成するには、新規テキストファイル(ファイル名は基本的に「robots.txt」)に必要なコードを記述してサーバーにアップします。
その後は、サーチコンソールの「robots.txt テスターツール」を利用して、そこから新しいrobots.txtファイルの作成や既存のrobots.txtファイルの編集を行い運用すると便利です。
※参考:robots.txtの動作確認方法
制御したいクローラーを指定する
Googlebotと呼ばれるメインのクローラー以外にも、クローラーは複数の種類があります。
その中からあらかじめ公式サイトで定義されてるクローラー名を「User-Agent」を使って指定して、クロール制御(制限)の記述を開始する形になります。
全てのクローラーを指定する場合
|
1 |
User-Agent:* |
Googleのクローラーを指定する場合
|
1 |
User-agent: Googlebot |
Google画像検索のクローラーを指定する場合
|
1 |
User-agent: Googlebot-Image |
サイト運用初期や通常は、すべてのクローラーを対象にすることが多いので、基本的にUser-Agentはワイルドカードの1つとなる「*(アスタリスク)」を指定しておくとよいでしょう。
その他のUser-Agentは、ホームページを運用してる間に必要あれば、利用する形になります。
クロールを制限する
クロールを制限するには、「User-Agent」の記述と共に、「Disallow」を使ってクロール拒否したいページやディレクトリのURLパス(ルートドメインに対する相対URL)を記述する形になります。
ディレクトリの場合
|
1 2 |
User-Agent:* Disallow: /example/ |
ページの場合
|
1 2 |
User-Agent:* Disallow: /example/sample.html |
サイト全体の場合
|
1 2 |
User-Agent:* Disallow: / |
このように、「Disallow」にファイル名を記述して、ページやディレクトリを絞り込むことでクロール制限したいファイルが限定できます。
robots.txtではあくまでもクロールの拒否ということを認識しておきましょう。
ちなみに、検索エンジンからのアクセスを拒否したい場合は、robots.txtと併用して、.htaccessファイルでのパスワード保護やnoindexタグを組み合わせて使う手段があります。
クロールを許可する
クロール拒否の指定ができる「Disallow」と真逆の「Allow」ですが、この記述はわざわざ書かなくてもデフォルトがクロール許可となるので、使う機会が少ないのが現状です。
では、実際にどんなときに使うかというと、すでに「Disallow」を使っていて、特定のページやディレクトリだけクロール許可したい場合にAllowを指定する使い方になります。
特定のページのみ許可する場合
|
1 2 3 |
User-agent: * Disallow: /example/ Allow: /example/sample.html |
このように、「Allow」にページやディレクトリのURLパスを記述して、特定のファイルへクロールを促すことができます。
サイトマップを知らせる
サイトマップはhtml形式やxml形式が多くありますが、いずれにせよクロールされやすい状況にあるか否かが、この「Sitemap」の記述の使い分けとなります。
なので、例えば、XML形式であればWebページから直接リンクが辿れないので、robots.txtにURLパスを記述しておくと、クローラーが見つけやすくなるので効果的です。
HTML形式(sitemap.html)なら、だいたいTOPページなどの重要なページから直接リンクされてクロールされやすい状態なので、そこまで記述する必要性はないでしょう。
XMLサイトマップの場所をクローラーに知らせる場合
|
1 2 3 4 |
User-Agent:* Disallow: Sitemap:http://example.com/sitemap.xml |
このように、Sitemapにサイトマップのパスを記述することで、クロールを促すことが可能です。
複数ある場合には改行して記述しましょう。
robots.txtの動作確認方法
robots.txtを設置しても、記述が正しくないとクローラーの動作をコントロールできません。
そこで、Googleのサーチコンソールに搭載されてる「robots.txtテスター」を使って、公開したrobots.txtの記述が正しいか?うまく動作してるか?内容を以下のような手順で確認することが重要です。
①まず、サーチコンソールにログイン後、左メニューの「クロール」>「robots.txt テスター」をクリックします。
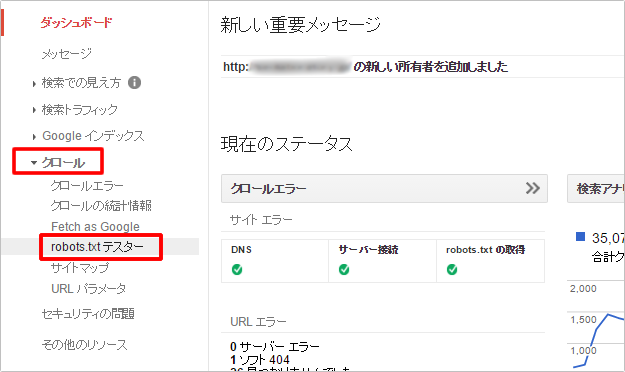
②すると、ご覧のように現在公開されているrobots.txtが表示されます。(ない場合は「robots.txt が見つかりません(404)」と表示されます。)
ここではURLを入力して「テスト」をクリックすると、robots.txtが正しく動作しているかどうか確認することができます。
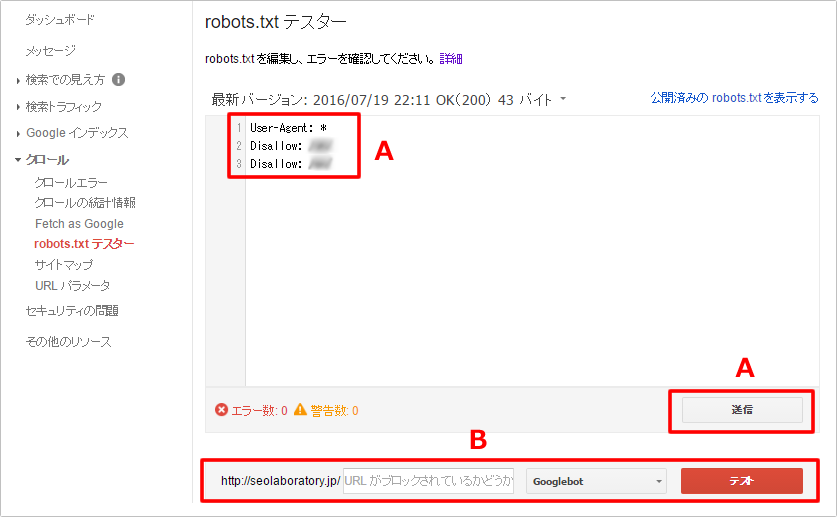
③robots.txtのDisallowページやディレクトリを記述し、プルダウンリストでエージェントを選択後、「テスト」ボタンをクリックします。
すると、以下のように該当コードが赤くハイライトされて、下部に「ブロック済み」と表示されるので、正しくブロックされてることが確認できます。
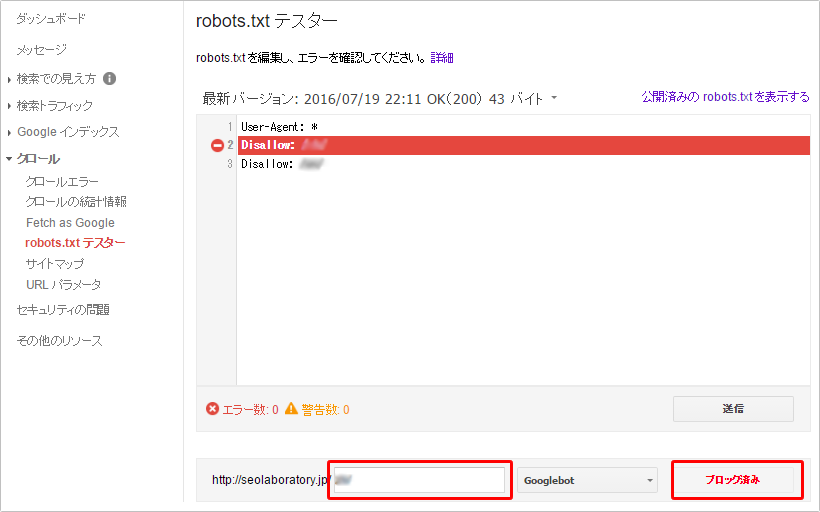
このように、robots.txtに記述した内容が正しく動作してるか?確認して、必要に応じて確実にクロール拒否することがサイトのパフォーマンスを管理するうえで重要と言えます。
robots.txtを活用する上での注意点

robots.txtを活用する上で、Webサイトへの影響や使い分け、挙動などを理解しておく必要があります。
なので以下のような注意点を念頭に入れた上で、robots.txtをサイト運用に役立てましょう。
- robots.txtの記述内容が反映されるまでにタイムラグがある。
- Webページのクロールは拒否するが、ユーザーはそのWebページにアクセスできる。
- アドレスバーにURLを入力すれば、robots.txtの内容が外部に見られる。(例:http://example.com/robots.txt) 見られたくない情報があればアクセス制限を欠けて対処しておきましょう。
- 重複コンテンツの対処法としては不完全なので、適切にな方法で対処する
- 数千以下のURL数(数千ページ以下)であれば、基本的にrobots.txtでクロール最適化を行う必要性は低い
このような点を意識して効果的にrobots.txtを活用しながら、重要なページをインデックスさせるなど、サイトのパフォーマンス管理に役立てることが大切です。
まとめ
robots.txtを必要に応じて活用し、サイトのパフォーマンスを管理しましょう。
重要なWebコンテンツがGoogleにしっかり認識されるようにリンクやファイルサイズなど最適化しながら、サイトの質を上げるようにSEO対策を進めることが大切です。
SEO対策しても検索順位が上がらない…なぜ?
SEO対策しても検索順位が上がらない…なぜ?
検索順位が上がらない理由は、SEO対策の質が低いからです。
例えば、ユーザーの検索意図を無視したり、関連性の低いコンテンツを増やす、内部リンクの最適化など疎かにします。
この場合、SEO対策の質が下がります。
そうなれば、ページやサイト自体の品質が上がらないので、Googleに評価されづらくなります。
結果、検索順位が上がらないというわけです。
こうした悪い状況を回避する為に、サイトの欠点を調査して上位化に必要な対策をご案内します(無料)。
検索順位を上げたり、検索流入を増やすにはSEOが重要!